Spam classification using classic models
Spam Classification
This is the final assignment of undergraduate elective course of UCAS: Data Mining, which may be helpful to you.
Problem Description
problem link: https://challenge.datacastle.cn/v3/cmptDetail.html?id=352
Given email text information, establish a classification model to determine which emails are spam.
Phone Number Checker
1.Theory
After downloading the training and testing data, I observed the spam text in the training set, trying to find some obvious features. I found that the vast majority of spam emails would contain “phone numbers”, usually a string of 11 in length, sometimes connected by characters such as spaces or ‘-‘ in the middle of the numbers.

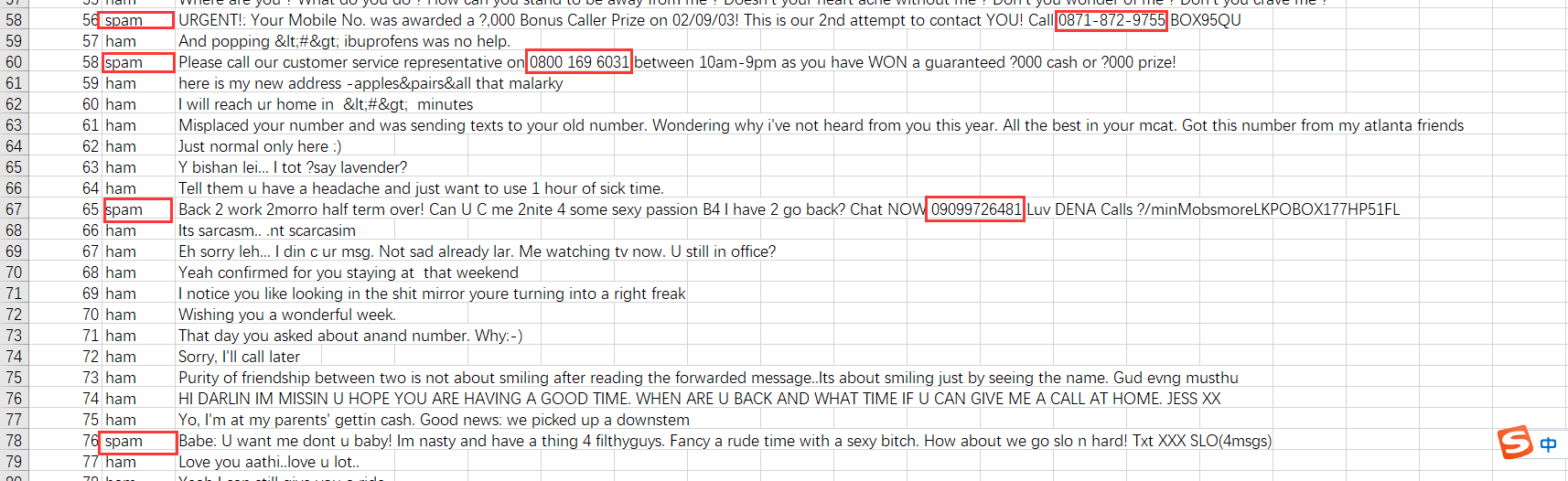
So a natural idea is to mark all emails with phone numbers as spam, otherwise they are considered normal emails. Method for identifying phone numbers: Use a sliding window to check all consecutive 13 digit strings in the text. If 9 or more digits are digits, it is considered a phone number. For example, “0871-872-9755” will be recognized as a phone number.
2.Code
Critical Code:
1 | |
3.Result

The accuracy on the training set is about 0.9457, and the accuracy on the test set is about 0.9434.
The initial way to identify phone numbers was to have 11 or more digits in a 13 length sliding window, with an accuracy rate of 0.9372.
It was discovered that some numbers were less than 11 digits and should still be recognized as phone numbers. The method of identifying phone numbers was changed to a 13 length sliding window with 9 or more digits. The accuracy of the test set was improved to 0.9434.
Naive Bayes regression model based on bag of words
1.Theory
Build a big word bag for all spam emails and a big word bag for all normal emails.
First, calculate the prior probability: take the proportion of spam and normal emails in the training set samples as the prior probability.
Then multiply the frequency of each word appearing in spam emails to obtain the probability that the email is spam, and multiply the probability of each word appearing in normal emails to obtain the probability that the email is normal. Compare the two probabilities and take the larger one as the prediction result.
Laplace smoothing was used to avoid the problem of calculating a probability of 0 when the frequency of a word in the bag of words is 0.
2.Code
Critical Code:
(1) Data Processing:
1 | |
(2) Prediction:
1 | |
3.Result

(1) Training time
The total time of training and prediction is 6.44s
(2) Accuracy on the training set
Accuracy on the training set is 0.9850
(3) Accuracy on the test set
The accuracy is 0.9452 without processing the numerical string.
Considering that phone numbers are a string of numbers, each spam phone call is different, but essentially can be seen as the same word. In order to make them play their due role, I converted all numbers to the number 0, and the accuracy was improved to 0.947.
At first, when dividing words, I directly deleted punctuation marks:
text = re.sub(r’[^\w\s]’, ‘’, text)
Later, it was discovered that some words separated by symbols did not have spaces in between, such as ‘… ‘, After removing punctuation marks, the two words became connected, so I changed the data processing method to replace punctuation marks with spaces:
text = re.sub(r’[^\w\s]’, ‘ ‘, text)
The accuracy has been improved to 0.9587.
Naive Bayes Model Based on TF-IDF
1.Theory
Email text initialization:
- Replace punctuation with spaces
- Replace all numbers with ‘0’
- Convert all letters to lowercase
- Divide each word into one or more spaces
- Merge the segmentation results into a string with only one space between each word
Call CountVectorizer() to segment each email into $n$ small word bags. Assuming all texts have m different words, each sample have $m$ features, representing the number of times each word appears in the email.
Call TfidfTransformer() to calculate the TF-IDF value of each small bag of words. At this point, the $m$ features of each sample become the corresponding TF-IDF values of $m$ words in the email text.
At this point, only a Multidimensional Feature Classification problem needs to be solved, which can be predicted through various methods such as naive Bayes model, logistic regression, support vector machine, etc.
2.Code
Critical Code:
(1) Data Processing:CountVectorizer() was called to construct the bag of words, and TfidfTransformer() was called to calculate the TF-IDF value.
1 | |
(2) Model training: MultinomialNB() was called to implement a Naive Bayes model with a prior of polynomial distribution.
1 | |
3.Result

(1) Training time
The total training and prediction time is 0.27s
(2) Accuracy on the training set
The accuracy of prediction on the training set is 0.9901.
(3) Accuracy on the test set
The accuracy of prediction on the test set is 0.9847.
Logistic regression
1.Theory
By constructing TF-IDF as input features in the manner described above, it can be transformed into a classification problem with multidimensional features, and a logistic regression model can be used for prediction.
2.Code
Critical Code:
(1) Data Processing:Data Processing consistent with the naive Bayes model based on TF-IDF
(2) Model training: LogisticRegressionCV was called to implement the logistic regression model
1 | |
3.Result

(1) Training time
The total training and prediction time is 1.63s
(2) Accuracy on the training set
The accuracy of prediction on the training set is 1.0
(3) Accuracy on the test set
The accuracy of prediction on the test set is 0.9865
SVM
1.Theory
By constructing TF-IDF as input features in the manner described above, it can be transformed into a classification problem with multidimensional features, and a SVM model can be used for prediction.
2.Code
critical code:
(1) Data Processing: It is basically the same as the Bayesian model and logistic regression model based on TF-IDF, with the only difference being the need to convert ‘ham’ and ‘spam’ into 0 and 1.
(2) The training process only changed the called model, and the other steps are basically the same.
1 | |
3.Result

(1) Training time
The total training and prediction time is 0.35s
(2) Accuracy on the training set
The accuracy of prediction on the training set is 0.9978
(3) Accuracy on the test set

The accuracy of prediction on the test set is 0.9874
Other classification models (Decision Tree, Random Forest, Multilayer Perceptron)
1.Theory
Due to their data processing methods being roughly consistent with the Bayes, Logistic Regression, and SVM based on TF-IDF mentioned above, all of which are packet switching solutions for a multidimensional feature classification problem, they will not be further elaborated。
2.Code
Decision Tree:
1 | |
Random Forest:
1 | |
Multilayer Perceptron:
1 | |
3.Result
Decision Tree:


Training time is 0.72s.
The accuracy of prediction on the training set is 0.9981.
Accuracy on the test set is 0.9390.
Random Forest:


Training time is 3.37s.
The accuracy of prediction on the training set is 0.9997.
The accuracy of prediction on the test set is 0.9874.
Multilayer Perceptron:


Training time is 8.51s.
The accuracy of prediction on the training set is 0.9968.
The accuracy of prediction on the test set is 0.9919.
Combination Model
1.Theory
I have implemented a Bayesian model and a Logistic Regression model based on TF-IDF, and their prediction accuracy is not much different.
Considering how to combine them, a natural idea is to let the two models make separate predictions. If the prediction results of the two models are the same, it is considered as the prediction result. Otherwise, we will use other methods to determine whether it is spam.
I printed out all the email texts with different prediction results from two models:
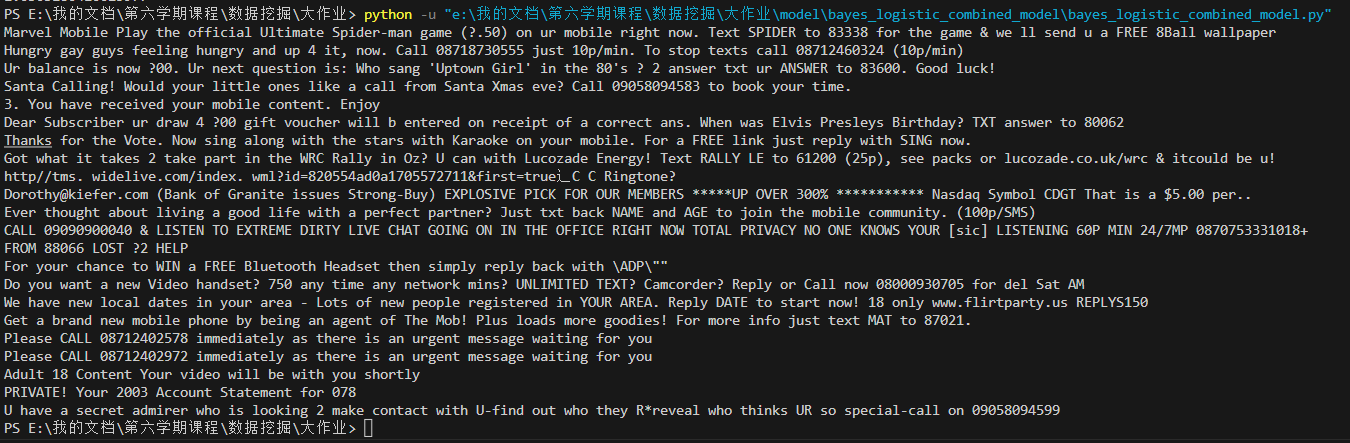
I found that most of these samples are spam emails. I guess both models have a tendency to predict some spam emails as normal emails, so a simple judgment method was adopted: all emails with different prediction results from the two models were treated as spam emails.
I also tried using Bayesian model, logistic regression model, and support vector machine model to predict simultaneously, and then selected the most frequently occurring classification from the three results as the final classification, but the performance did not improve on the test set. But if samples with different results among them are treated as spam emails, their scores on the test set will be improved.
Afterwards, I tried using five models including Bayesian, logistic regression, SVM, random forest, and MLP for simultaneous prediction. The prediction results of the five models were voted to obtain the final result, but there was no improvement in accuracy on the test set. Considering that the model has a tendency to predict some spam emails as normal emails, I attempted to take spam as the final result if any of the five models predicted it as spam. The accuracy of the results on the test set was improved.
2.Code
critical code:
(1) Bayes and logistic regression combination model:
1 | |
(2) Five models combination:
1 | |
3.Result


(1) Training time
Combination of two models: The total training and prediction time is 1.91s.
Combination of five models: The total training and prediction time is 12.20s.
(2) Accuracy on the training set
Combination of two models: The accuracy of prediction on the training set is 1.0.
Combination of five models: The accuracy of prediction on the training set is 0.9991.
(3) Accuracy on the test set
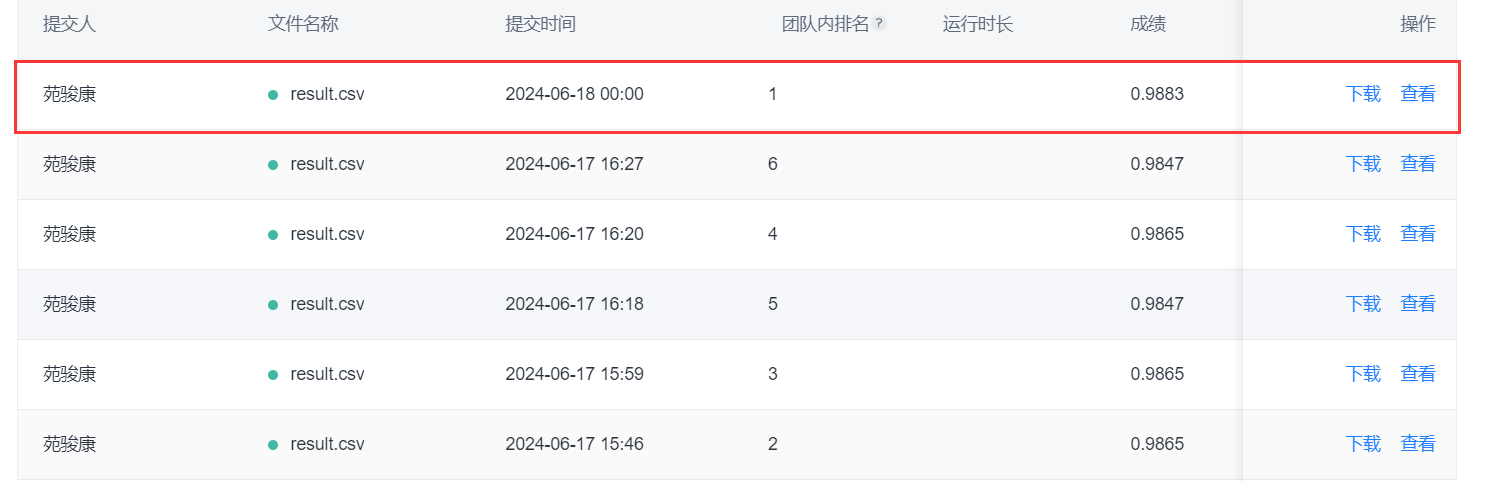

Combination of two models: The accuracy of prediction on the test set is 0.9883.
Combination of five models: The accuracy of prediction on the test set is 0.9919.
Result and Summary
Ranking

As shown above, among all the prediction results I submitted, the highest accuracy on the test set was 0.9919, ranking 11th
Comparison of different models
| Model | Training time | Accuracy on the training set | Accuracy on the test set |
|---|---|---|---|
| Phone Number Checker | - | 0.9457 | 0.9434 |
| Bayes Classifier based on Bag of Words | 6.44s | 0.9850 | 0.9587 |
| Bayes Classifier based on TF-IDF | 0.27s | 0.9901 | 0.9847 |
| Logistic Regression | 1.63s | 1.0000 | 0.9865 |
| SVM | 0.35s | 0.9978 | 0.9847 |
| Decision Tree | 0.72s | 0.9981 | 0.9390 |
| Random Forest | 3.37s | 0.9997 | 0.9847 |
| MLP | 8.51s | 0.9968 | 0.9883 |
| bayes-LR Combination Model | 1.91s | 1.0000 | 0.9883 |
| bayes-LR-SVR-RF-MLP Combination Model | 12.20s | 0.9991 | 0.9919 |
Summary
Phone number checking was a small attempt made by observing the characteristics of spam emails in the training set, and the effect was quite good.
The accuracy of the Bayesian classifier based on TF-IDF is much higher than that based on bag of words, and the former is also much faster in training speed than the latter.
Among these TF-IDF based models, Bayesian classifiers, logistic regression, support vector machines, random forests, and multi-layer perceptrons all have good accuracy on the training set. Among them, the multi-layer perceptron has the longest training time and the highest accuracy on the test set. The training time for Random Forest is the second longest. The accuracy of logistic regression is slightly better than SVM and Bayesian classifiers, but the training speed is slower compared to them.
Originally, it was expected that the accuracy of the multi-layer perceptron would not be very high because its expressive power was too strong and it was prone to overfitting. However, surprisingly, it was the model with the best accuracy on the test set.
The decision tree exhibits overfitting, which may be related to its strong expressive ability and small dataset size.
The Bayesian logistic regression combination model also has good accuracy on the test set, and the combination model of the five models can achieve the best accuracy, indicating that these individual models do have a tendency to predict spam emails as normal emails on the test set.
Areas that can be improved:
Each model is directly adjusted and uses default parameters without parameter tuning. Some models may improve their performance after parameter tuning
The text preprocessing is relatively rough and does not recognize and process special strings such as URLs, links, and garbled characters
Without multiple training sessions, the ‘Training time’ may not be precise
The “combination” between models is relatively simple and crude, and the single model’s “tendency to predict spam into normal mail” has not been explained in principle
In terms of interpretability, perhaps one or more collaborative formulas can be used for prediction, which has better interpretability and facilitates monitoring and correction